Engineering reasoning LLMs: Notes and Observations
Reasoning models are LLMs that are designed to tackle complex tasks that require multiple steps of reasoning. OpenAI’s o1 was the first mainstream reasoning model, and showed remarkable results on highly complex questions. A torrent of papers were published subsequent to o1, each exploring how to build these types of systems. Most recently, DeepSeek-R1 has captured attention as a state-of-the-art reasoning model with a published methodology.
Collectively, all these papers have shown a path to building a high-quality reasoning model. I called this post “engineering reasoning LLMs” because, thanks to the efforts of OpenAI and researchers around the world, building reasoning models is now more of an engineering effort than a pure research exercise. That said, there is still an enormous amount of experimentation required to build the model — but the general direction and shape of the experiments are clearer than ever.
Here are my notes and observations.
- DeepSeek-R1: From Researchers to Practitioners
- Reasoning data is largely synthetic
- Open reasoning datasets are scarce
- Reinforcement Learning
- Process reward models
- Inference time (test time) reasoning
DeepSeek-R1: From Researchers to Practitioners
DeepSeek-R1 was the first high quality open weight reasoning model that shared details of the training methodology (QWen-32B-Preview was shared before DeepSeek-R1, but the training methodology details have not been publicly disclosed.)
DeepSeek-R1’s innovation is not in any particular ML technique, but in the novel application of well-known training strategies (in particular, reinforcement learning and supervised fine-tuning). More generally: DeepSeek-R1 shows that building high quality reasoning models is now within the province of a small team of (expert) practitioners, and not just researchers.
Reasoning data is largely synthetic
Modern reasoning models are largely trained on synthetic reasoning data. By synthetic, I refer to data created by other LLMs, as opposed to data created by humans.
- DeepSeek-R1 uses 600K CoT SFT examples from DeepSeek-R1-Zero plus 200K knowledge-based SFT examples created using DeepSeek-V3
- Sky-T1 uses QwQ-32B-Preview to generate the initial training data set, and then use GPT-4o-mini for formatting. (QwQ-32B is a reasoning model that was released before DeepSeek-R1.)
- STILL-2 uses both DeepSeek-R1 and QwQ-32B-Preview to generate its initial dataset.
Furthermore, both DeepSeek-R1 and STILL-2 use an iterative training process, where additional training data is generated by intermediate models prior to the final model artifact.
Open reasoning datasets are scarce
While DeepSeek-R1 and Qwen-32B-Preview are open source, the actual reasoning data for these models is not. This is generally true as well for foundation models (e.g., Llama3), but few organizations are creating their own foundation models from scratch.
That said, there are a few clues on how to build reasoning data sets. The Open Thoughts project is working on aggregating open source, high quality, reasoning datasets. The OpenThoughts-114k is a dataset that is built on reasoning traces created by DeepSeek-R1.
In addition, the system prompt used by Sky-T1 is instructive (any typos are from the source code, not mine):
Your role as an assistant involves thoroughly exploring questions through a systematic long \
thinking process before providing the final precise and accurate solutions. This requires \
engaging in a comprehensive cycle of analysis, summarizing, exploration, reassessment, reflection, \
backtracing, and iteration to develop well-considered thinking process. \
Please structure your response into two main sections: Thought and Solution. \
In the Thought section, detail your reasoning process using the specified format: \
<|begin_of_thought|> {thought with steps separated with '\n\n'} \
<|end_of_thought|> \
Each step should include detailed considerations such as analisying questions, summarizing \
relevant findings, brainstorming new ideas, verifying the accuracy of the current steps, refining \
any errors, and revisiting previous steps. \
In the Solution section, based on various attempts, explorations, and reflections from the Thought \
section, systematically present the final solution that you deem correct. The solution should \
remain a logical, accurate, concise expression style and detail necessary step needed to reach the \
conclusion, formatted as follows: \
<|begin_of_solution|> \
{final formatted, precise, and clear solution} \
<|end_of_solution|> \
Now, try to solve the following question through the above guidelines:Reinforcement Learning
The first generation of LLMs (e.g., GPT-3, LlaMA) were primarily pre-trained on Internet-scale datasets, fine-tuned for specific tasks, and then aligned using reinforcement learning with human feedback.
Reasoning models such as OpenAI o1, DeepSeek-R1 and Sky-T1 now extend this core recipe by using reinforcement learning with a verifiable reward model on top of a known high quality foundation model. This explains the popularity of mathematics and coding for training and testing, as the correctness of answers is relatively easy to assess. As a direct point of comparison, Sky-T1-7B outperforms OpenThinker-7B on math benchmarks. Both are are built on highly similar foundation models (Qwen2.5-Math-7B and Qwen2.5-Instruct-7B). The key difference is that Sky-T1-7B uses RL on a small (5K) data set, while OpenThinker-7B is fine-tuned using the much larger OpenThoughts-114K dataset.
Process reward models
A reward model is a specialized model that will score the output of an LLM. There are two general types of reward models for LLMs:
- outcome reward models (ORMs), which score the final output of an LLM
- process reward models (PRMs), which score the quality of each step in a reasoning process
Nemotron-4-340B-Reward) is a high-quality ORM built on Nvidia’s base Nemotron-4-340B foundation model. The Reward model that will output one of five scalar values based on five different attributes (e.g., helpfulness, coherence, etc.).
OpenAI showed how using using a process reward model can dramatically improve reasoning performance on mathematics testing. PRMs are in some sense a more specialized form of reasoning model. Both reasoning models and PRMs are trained on reasoning traces; the difference is that in a PRM, there are specific scores associated with each step of the process.
I haven’t tried it, but Stephen Diehl has written a tutorial on how to build a process reward model. My current hypothesis is that using a PRM strategy in training, similar to the OpenAI paper, will probably be superseded by generalized training on reasoning data. That said, I’m very curious if there is potential for PRMs at inference-time to improve reasoning performance.
Inference time (test time) reasoning
Training is not the only way to improve performance. Crucially, performance can be improved at inference time (aka test time). Back in 2022, researches found that adding “Let’s think step-by-step” to a prompt measurably improved performance. This launched the Chain-of-Thought (CoT) line of prompt engineering.
Recently, interest in improving performance at inference time has skyrocketed, with a wide range of techniques published that all improve performance over baseline.
My first exposure to a systematic evaluation of inference-time scaling was this paper from Google DeepMind. The team systematically evaluated how to scale inference time compute to improve model performance by employing two inference-time strategies: an inference-time PRM (as opposed to the training-time PRM used in the OpenAI paper), and an answer introspection and revision strategy. One of their discoveries was that optimal strategy was highly problem dependent.
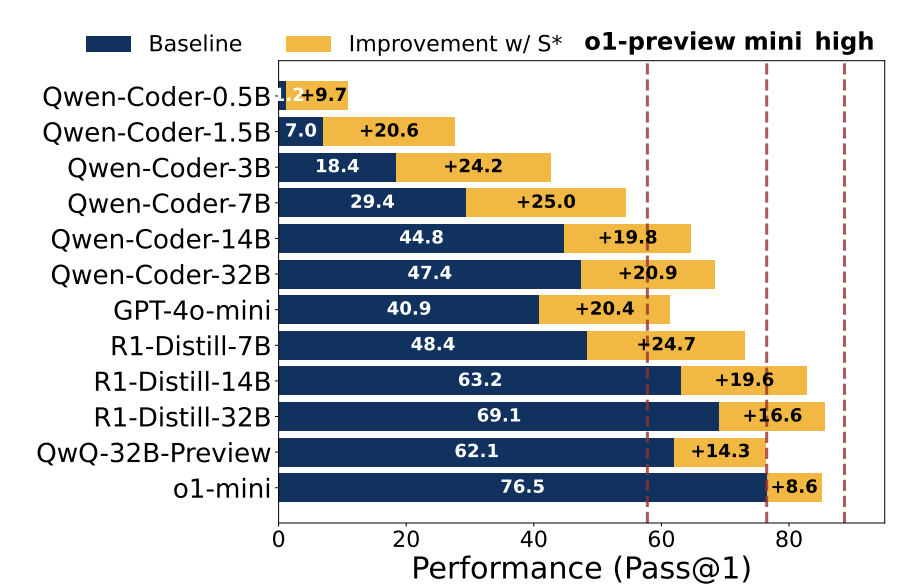
The Sky-T1 team published a paper in February 2025 that introduced a test-time scaling technique focused on code generation (previously, much of the inference-time scaling research has focused on math problems), and showed how layering in inference time compute on a variety of existing models (Qwen-Coder, GPT-4o-mini, R1-Distill) can substantially improve performance.
Building a reasoning model today
I believe building a high-quality, domain-specific reasoning model is now within reach for many organizations. While a non-trivial task, the strategies listed above (training on synthetic reasoning traces, reinforcement learning, process reward models, and inference-time scaling) are now well-established. The challenge is to experiment with the right combination of strategies to produce optimal reasoning performance.